Abbreviations:
- Xplain Data CausalDiscoverer : XCD
- Xplain Data ObjectAnalytics : XOA
- Xplain Data ObjectExplorer : XOE
- Xplain Data AdminTool : XAT
- Causal Discovery : CD
Why should I use XCD and not any other CD algorithm?
-
Typical CD algorithms scale very badly in the number of variables and are therefore usually not usable in real-world environments. XCD relies on ObjectAnalytics, meaning that data is restructured such that all relevant information for an object is readily available and does not have to be looked up in a relational database. This leads to a much better scalability in the amount and dimensionality of the data, which is absolutely essential for Causal Discovery, as we have to be sure not to exclude any potential confounders!
-
Moreover, typical CD algorithms do not incorporate the notion of time and therefore often have problems with finding the correct causal direction. Without incorporating time, finding the causal direction is a big challenge mathematically. However, with the use of timestamps, this problem becomes trivial, as the cause always happens before the effect.
For instance, the following survey
over 40 pages has only this small paragraph on causality and time
-
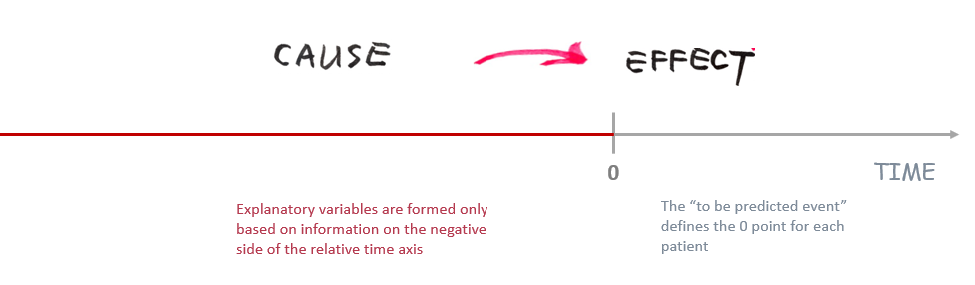
If we want to find causes for any target, we have to put all of the events on a so called Relative Time Axis (more information further below), meaning that I only consider events which have happened before the target. Again, this may sound trivial, but computing a query like this is extremely easy and performant in an ObjectAnalytics setting, but very inefficient to compute for example in SQL!
-
You may simply plug all of your available data and variables into the model - the algorithm will perform variable selection automatically for you and it can easily handle even millions of variables! The reason for this is that at no point do we have to materialize a flat table with millions of columns - ObjectAnalytics is much more performant!
-
This also means that once the data is loaded into the XOE, the same setup can be used for any analysis question or target I want to research. In contrast to this, note that in a typical setting, for any new research target the Data Scientist has to create a new dataframe which is suited for the particular task.


How can I run an XCD model on my data?
-
Define a target by making a selection in the XOE. By clicking on the lightbulb, a xmodelconfig file suited for the desired target may be loaded.
-
Before an XCD model can be run, such a model config has to be created first (see further below for more information). In essence, this model config defines the search space. The resulting xmodelconfig-file is in JSON format and must have a certain structure. They can, however, also be directly created in the XOE with only a couple of clicks.
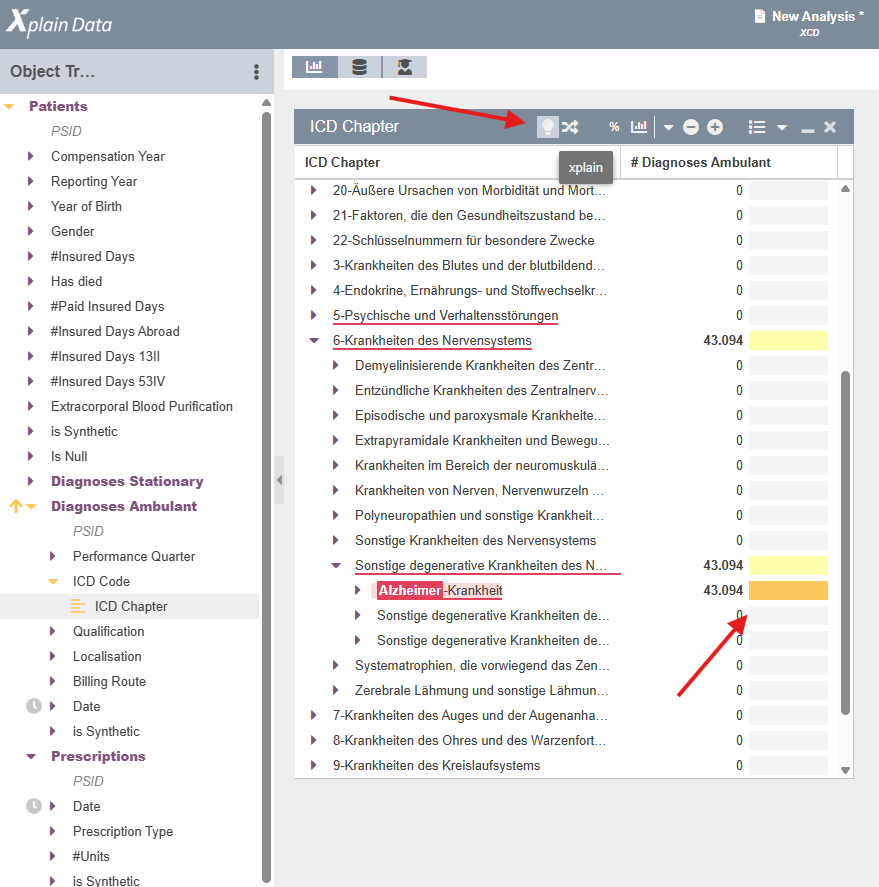
How should my data look to get as reliable XCD results as possible?
- To get meaningful XCD results, the data should consist of multiple sub-objects, which all have timestamps appended to them. These timestamps are used to consider only those factors which have happened before the target. In general, the more variables and relations between them are in the data, the better the strength of XCD comes into play in comparison to standard Causal Discovery Algorithms.
What if I don’t have timestamps for my objects?
- If no timestamps are given, it usually requires human input to decide which of these variables makes sense to use. From the domain, it should often be known which of these variables happen before or after the target. Events that happen after the target must not be used to explain the target!
What are the results of an XCD run?
- In its simplest form, XCD returns a list of direct factors for the target. If, however, also indirect (higher level) factors are needed, a so called Causal Pathway Graph can be computed. It contains both direct and indirect effects and, unlike a standard DAG, contains the temporal relations between the variables.
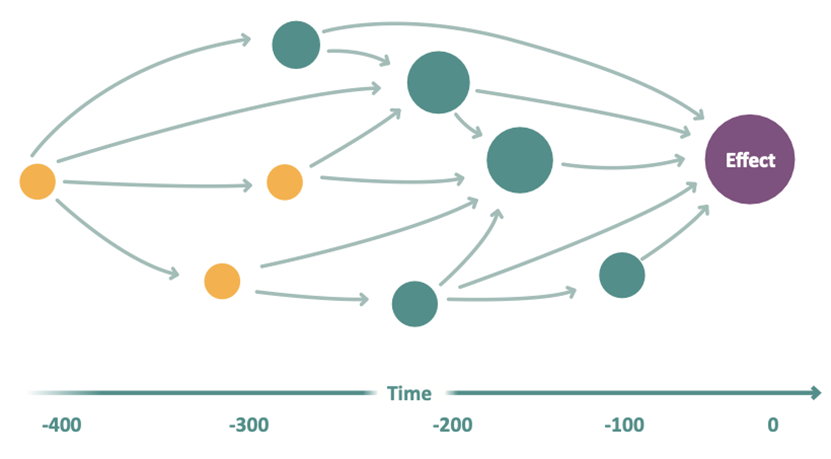
Why Causal Pathways and not a DAG?
- XCD results are always in focus with a certain target event – they do not aim at computing a whole DAG out of the data, as typically the search space consists of millions of variables (consider a electronic health record) and a DAG with millions of nodes and edges is not human-readable. For all nodes, both their direct and indirect causal effects/contributions on the target are computed, as well as the dependence structure between them, as this is what is typically sufficient.
Do I have to define the modelconfig file manually?
- Modelconfigs can be created automatically via the Causal Discovery View.
It requires minimal input from the user
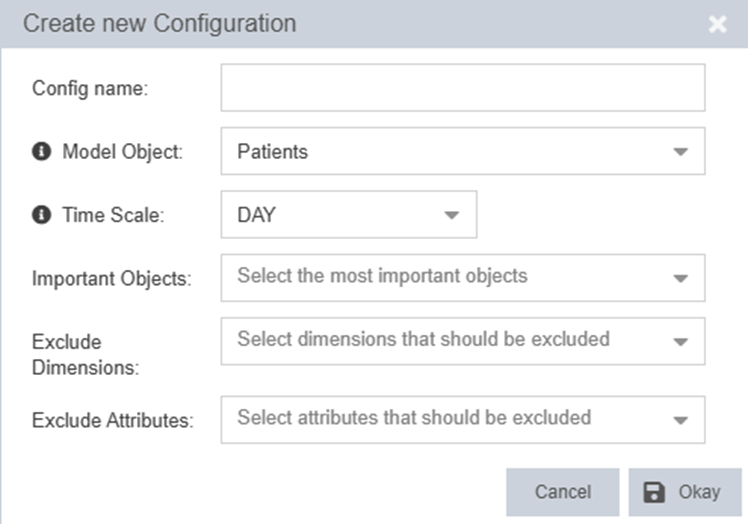
- Simply select the model object, which is typically the root. The model is computed by iterating over all instances of that object. Moreover, features will be built by aggregating information from other objects onto the model object. If you are not sure which model object to use, it often helps to simply state the causal discovery target in words: “Why are there model objects with target events?”
- The time scale defines in which time intervals to consider the events. This also defines how close and how far away from events to the target will be considered. In many scenarios, this will be “Day”, but in other cases such as in production, the time scale might also be “Seconds” or even “Milliseconds”.
- Important Objects: In the easiest case, we may simply use all of the available objects. However, sometimes it is clear with some domain knowledge that not all of the objects are needed or that a smaller model will suffice first.
- Exclude Dimensions / Exclude Attributes: for the chosen objects, we can select single dimensions or attributes to not be included into the model. The reason for this is manifold. It may be the case that there are trivial explanations for the target prohibiting other, more interesting factors, to come up. It may also happen that some events have no timestamp but it is known that they happened after the target. In this case, the corresponding dimension or attribute must not be used for model building!
What is the general logic behind the XCD algorithm?
- The XCD model puts the target event on a relative time axis. Then for each object instance millions of variables from the events that have happened before the target event are built. From these millions, a handful of causal factors are searched for. This would correspond to running a DAG-learning algorithm on a table with millions of columns (not feasible!).
What does the auto modelconfig do?
- The auto modelconfig basically defines the search space, i.e., the features to be built from the variables in the data, which will then be considered as causal factors for the target. This includes in particular the time buckets in which the events may fall as well as the aggregation functions with respect to which the data is aggregated.
How exactly does the auto modelconfig build features from the data?
-
Say you have selected a target event T and you want to explain it with some other dimension D. Remember that dimensions in the XOE are represented via its attributes, which are basically discrete intervals of values that D can take on. Assume that the attribute of interest has n intervals. Then the dimension d will be split into n Boolean variables, one for each interval in which the value of D could fall to. Note that this implies that the attributes need to be constructed properly, such that sufficient information is available. In practice, it can make sense to use multiple attributes for a dimension. One with a small number of intervals and one with a more detailed representation.
-
If the analysis is made on a time axis, then the n variables built like above are further split into more Boolean variables. Based on the chosen time scale, time buckets are built with respect to the target and it has to be checked whether the variables fall into the corresponding time buckets. In conclusion, the variables built will be of the form “Dimension D has taken on values [a1,a2] in the time frame [t1,t2] before the target has happened”.
-
The variables built above will then be further transformed by using certain aggregation functions. The most simple ones are COUNTs, but also other aggregation functions such as MAX,MIN,AVG and more are available. So, for example, one variable might count the number of times a dimension D has taken on certain values in a certain time frame. Another one might count the average of these multiple occurrences, and so on.
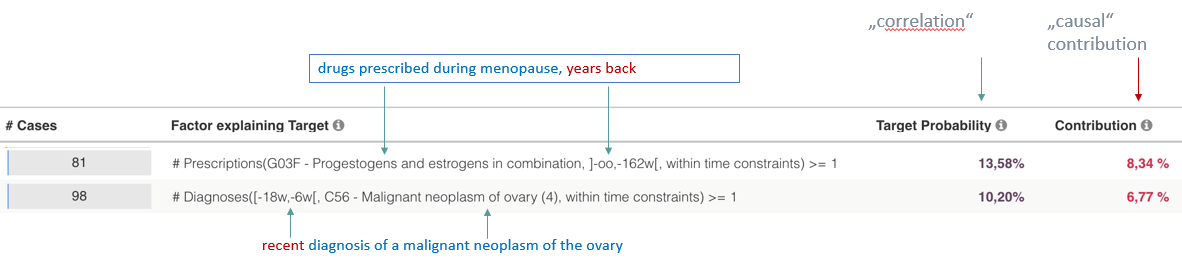
Are the results from the automatically generated modelconfig the best possible?
- Results from an automatically created modelfile have to be treated with care! Depending on the specific data, the modelfile might have to be edited manually. One of the most frequent reasons to do this is if the model result contains factors which explain the target almost perfectly. Typically, this is a trivial relation known to domain experts, but since its model fit is so good, it won’t allow any other, more interesting, factors to appear. Simply use the Exclude Dimensions / Exclude Attributes to further refine your model.
- Moreover, the automatic modelconfig tries to set up the search space automatically as well as possible. However, sometimes you want to refine some details, like the definition of the time buckets or the choice of aggregation functions, manually. You can do this by editing the xmodel JSON file in the model center.
What is the recommended best practice to create a modelconfig file?
- Start with a simple automatic modelconfig like above. If the results are not satisfactory yet, it usually means that some dimensions from objects have to be either added or deleted from the model, so simply create another auto-modelconfig. If after a couple of iterations, the results are still not satisfactory, the modelconfig file has to be edited manually with more detail. This can be done according to Causal Discovery Configuration — Xplain Data Manual documentation.
What are some easy ways to improve my model results?
- Dimensions are represented via their attributes. If these attributes contain either too many or too much intervals, it might lead to not significant results. Defining another attribute for that dimension might yield better results.
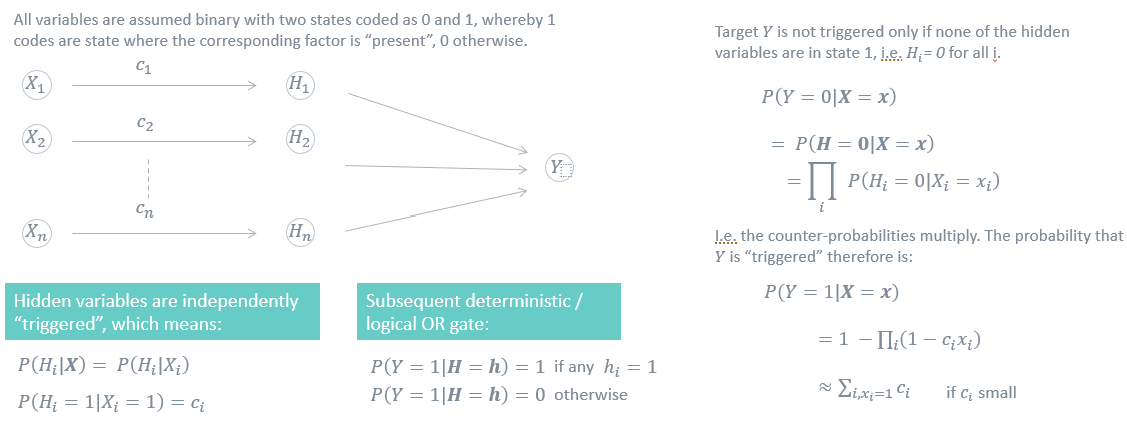
What is the mathematics behind the XCD algorithm?
- Noisy Or Gate, ICI Model